ChatGPT: Unpacking the constructs
ChatGPT is quite a popular LLM (Large Language Model) that is widely used these days across various lines of engagement from article editing (no need to write a fresh, just edit generated text), coding prototypes (e.g. asking to generate code for the login page of some web interface) to legal, corporate or home assignments. Very recently, I read an article about ChatGPT working as a lawyer to recover $109,500. However, such apps should be used to augment major tasks without damaging the creative instinct of human brains. ChatGPT is available as a demonstrable OpenAI API that can be used once you have an account created in OpenAI.
NLP (Natural Language Process) has evolved and improved over the years starting from the simple Bag of Words technique (importance of words being proportional to their frequency) to now GPT4 based (A newly trained LLM with a much-improved ability to encapsulate context and understanding). Transformer architecture revolutionized the idea to capture context and the relationship between words/tokens in documents using the encoder-decoder technique, whereas Sequence models viz. RNN (Recurrent Neural Networking) and LSTM (Long Short Term Models) were limited in capturing context within the fixed length. Multi-head parallel Self-Attention components in Transformer used in generating Q (Query), K(Key), and V(Value) vectors for each token while taking cosine similarities between Q and K to build values that helped in encapsulating contexts and relationships between words across long sentences. Please refer to the white paper to dig into the deeper concept of “Attention is All you Need”, which forms the foundation of the Transformer model.
How NLP has evolved over the years: BoW – Bag of Words ⇒ Word Embedding (Word2Vec) ⇒ RNN (Recurrent Neural Networking) ⇒ LSTM (Long Short Term Memory) ⇒ Transformer ⇒ BERT (Bidirectional Encoder Representation from Transformer) ⇒ GPT (1,2,3) ⇒ GPT 3.5 (Generative Pre-Trained Transformer) ⇒ InstructGPT ⇒ ChatGPT ⇒ GPT4 based LLM (work in Progress) and …..Continues
The above flow is an approximate representation of NLP maturity and not necessarily in absolute order è.g. BERT performs better in deciphering meaning or reasons whereas the GPT family performs better on long sentences.
NLP continues to evolve and is approaching AGI (Artificial General Intelligence) or general intelligence at the human level with speed and accuracy. Improvement in LLM boosts NLP in its performance, e.g. ML Translation engine performs better in multilingual translation by capturing context and central idea with the help of LLM such as GPT family, and BERT.
Unpacking the internals of ChatGPT: ChatGPT is an LLM that has been trained in a unique way that allows users to converse by generating human-like responses. A good understanding of LLM (e.g. GPT families), RM (Reward Model – Used primarily in Reinforcement Learning-RL), PPO (Proximal Policy Optimization – An algorithm to update policy weights in RL), Transformer architecture, RLHF (Reinforcement Learning from Human Feedback) is required to understand ChatGPT internals. This article outlines the basic concept and training steps. So let’s dive in with an image of the ChatGPT API interface
Training ChatGPT
Loss Function optimization plays a crucial role in ML training by updating the weights of each parameter in such a way that actual and predicted values are closer. ChatGPT model relies on human feedback as loss or gap between predicted and ideal text to optimize its language model. For example, let’s say, the predicted text is “Machine is better than Pen” as compared to the expected text “Machine runs faster than Pen in copying down texts” resorts trainer (human) to apply feedback in the learning process to bring response closer to human preference. The performance metrics are integrated into the learning process keeping human preference an essential factor. ChatGPT or its predecessor, InstructGPT, has been trained following RLHF (Reinforcement Learning from Human Feedback) method.
Language models (LM) are of two types, MLM (Mask Language Model) and CLM (Causal Language Model). The former type of model predicts missing words inside the sentence since it is trained by texts with masked word/s, whereas later predicts the next word that can appear at the end of a sentence as we see in mail applications (Gmail, Hotmail, etc,). LLM like the GPT family has been trained upon the huge corpus of text data from various sources viz. Internet, journals, Reddit, blogs, etc., and falls into the CLM category.
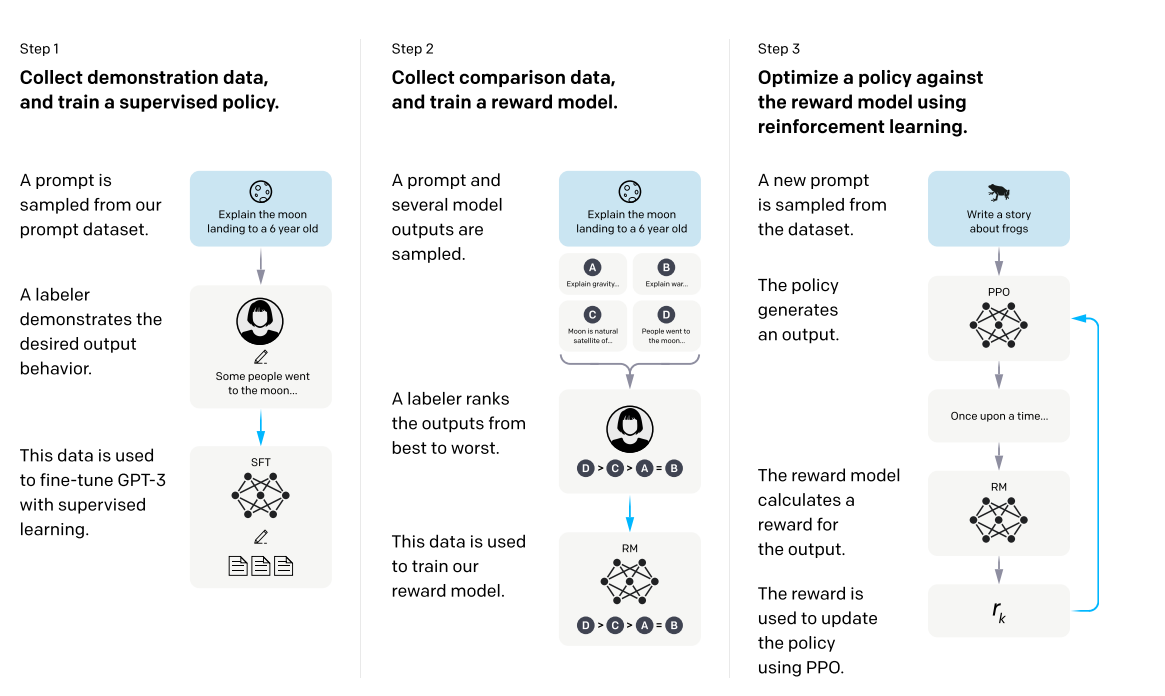
The following picture encapsulates the idea behind the whole training process for ChatGPT.
https://arxiv.org/pdf/2203.02155.pdf
ChatGPT training is a 3 steps process:- The Training process is termed RLHF, Reinforcement Learning using Human Feedback, which summarizes all involved steps as below:-
- Pretraining Language Model: The training process begins with an already pretrained LLM model, GPT-3. Such LLMs have been there for years and we have been using them for various uses such as document categorization (Sports, Politics, Entertainment, Food, etc. categorization), sentiments analysis, entity recognition (City, Organization, Celebrity, etc. identification), and many others. GPT-3 is further fine-tuned (SFT- Supervised Fine Tuning) using datasets with human-preferred responses to an enhanced version, GPT-3.5, which is later used to create an RM (Reward Model) in the next step.
- Reward Model development: RM is required to be used to optimize policy in the next RL (Reinforcement Learning) step of the RLHF process by using an algorithm called PPO (Proximal Policy Optimization). A pair of prompts and their ranked output forms the training dataset to train an RM. AI annotators (human trainers) were involved in ranking output responses e.g. Text(D)>Text(C)>Text(A)=Text(B). These pair of text blocks (Prompts and ranked output) constitute the training dataset to train the RM model that would output a normalized scalar value as a reward value, which is further used in the next RL process.
- The last step completes the training process (RLHF) of ChatGPT. As mentioned earlier, RL training technique has been used to optimize the policy of trained LLM GPT-3.5 from step 1.
- The original LLM GPT-3.5 with its policy from Step 1 is copied.
- Some prompts or input texts are passed through a. (Copied version of LLM)
- A response text is generated according to the policy in a.
- The generated text is passed through the RM (Reward Model) from step 2.
- RM calculates the reward, which is used to update the copied original policy in a.
- PPO is Policy Gradient Method in RL that is used to gradually update parametrized policy for the maximal long-term gain. PPO works like the adiabatic process in thermodynamics, by updating policy slowly while avoiding overfitting the model. It’s an iterative process until a positive change in reward stops.
- ChatGPT is finally trained to be deployed as OpenAI API.
Summary: ChatGPT training process involves RLHF (Reinforcement Learning from Human Feedback) and there are many such LLMs products viz. DeepMind, Anthropic have used the same. While the model has been trained with huge and varied datasets to capture semantic, context, and human preferences that reduce biases, hallucination, and incorrectness, but lacks explainability to be used in health and financial industries the least. It’s definitely a promising training technique and the recent GPT4 performance boost in accuracy and hallucination reduction, continues stirring up the race to produce products like BardAI while opening up Prompt Engineering as a new discipline. Consistent and continuous maturity in large language models brings us closer to AGI. Such LLMs can definitely be used to augment our regular and/or mundane business process e.g integrate with RPA or contact center bot, but we must be very cautious in allowing intervention in our creative space. ChatGPT training process involves a huge amount of data, mathematics, and processors to update 178 Billion neural network parameters to output human-like responses, One should refer to the white paper and/or OpenAI to understand the involved mathematics, the article is an attempt to highlight key concepts behind its training process.