


Imagine a passionate student, starting their journey to become a data scientist. At first, they immerse themselves broadly e.g. mathematics, programming, SQL, statistics, and machine learning fundamentals. Their early learning is wide and deep but not yet specialized for real-world needs. As the student progresses, they seek more focused knowledge: practical projects, mentorship, hands-on experience.Their growth must be graceful, they must specialize intelligently while preserving their broad foundational knowledge. If they rush too fast, changing their methods drastically after each project, they risk forgetting the fundamentals.If they move too cautiously, they miss new opportunities for growth.
The real art of becoming a great data scientist lies in adapting gracefully while staying grounded, aligning new feedback with foundational understanding.
Fine-tuning a pre-trained LLM should follow exactly the same philosophy. After building a broad, powerful foundation through pre-training, the next steps must carefully specialize the model, adapting it to new tasks without losing its original capabilities. Like a student evolving intelligently, a model must learn from new feedback while preserving its core strengths.
Scaling This Vision: Building India’s Foundational AI
Today, India stands at a similar point of inflection. We are gearing up to build our own foundational Large Language Models (LLMs): systems envisioned not just for general-purpose intelligence, but for domain-specialized expertise in areas like agriculture, healthcare, water management, education, and beyond. While data and compute are crucial enablers, true leadership will come from how smartly and safely we fine-tune and optimize these massive models. Across the world, projects are introducing exciting innovations:
- Extended Context Windows for longer memory and understanding
- Mixture of Experts (MoE) architectures for efficiency and specialization,
- Parameter Efficient Fine-Tuning (PEFT) methods for faster, lighter domain adaptation.
Initiatives like DeepSeek have demonstrated how architectural innovation can push boundaries. But architectural innovation alone is not enough.
The Foundation (How Pre-Training Mirrors Broad Learning): Just as the data scientist’s journey begins with mastering core fundamentals, the training of LLMs begins with pre-training, exposing models to a vast ocean of internet-scale text. Here, models like GPT-3.5, GPT-4, and others develop wide-ranging reasoning and language capabilities, but not yet task-specific behavior or human-aligned judgment. Pre-training builds a strong but raw foundation, much like the initial academic journey of a young learner.
Fine-Tuning (Moving Toward Specialization): Fine-tuning then becomes essential, shaping models toward real-world goals:
- Prompt Engineering: Crafting better prompts to extract better answers, akin to asking a smart but broad-minded student more precisely framed problems. (This method doesn’t update the weights of the pre-trained model; models follow instructions or examples (shots) to render expected responses. Larger models e.g. 50B+ parameters do a nice job here.)
- Instruction Fine-Tuning (SFT): Training on task-specific datasets, similar to a student solving targeted machine learning projects under mentorship. (This is called Supervised Fine-Tuning (SFT) where the model learns from labeled datasets and updates weights accordingly.)
- Reinforcement Learning from Human Feedback (RLHF):Going beyond static instruction, here human reviewers provide live feedback, guiding the model to adapt dynamically to human preferences, just as a mentor helps a student reason ethically and communicate clearly, not just answer technically.
At the Heart of RLHF is Proximal Policy Optimization (PPO): Fine-tuning with RLHF is powered by the beautiful optimization technique Proximal Policy Optimization (PPO).
PPO is the reinforcement learning algorithm used in RLHF to fine-tune LLMs ,maximizing rewards based on human feedback while carefully controlling how far the model drifts from its pre-trained knowledge.
Here’s the quick flow of RLHF in fine-tuning a pretrained model: (Pretraining ➔ SFT ➔ Reward Model Training ➔ PPO ➔ Final Aligned LLM). Now, let’s zoom into PPO, because it stands as one of the key differentiators in modern LLM training, and it represents a critical frontier where the next wave of innovation must focus.
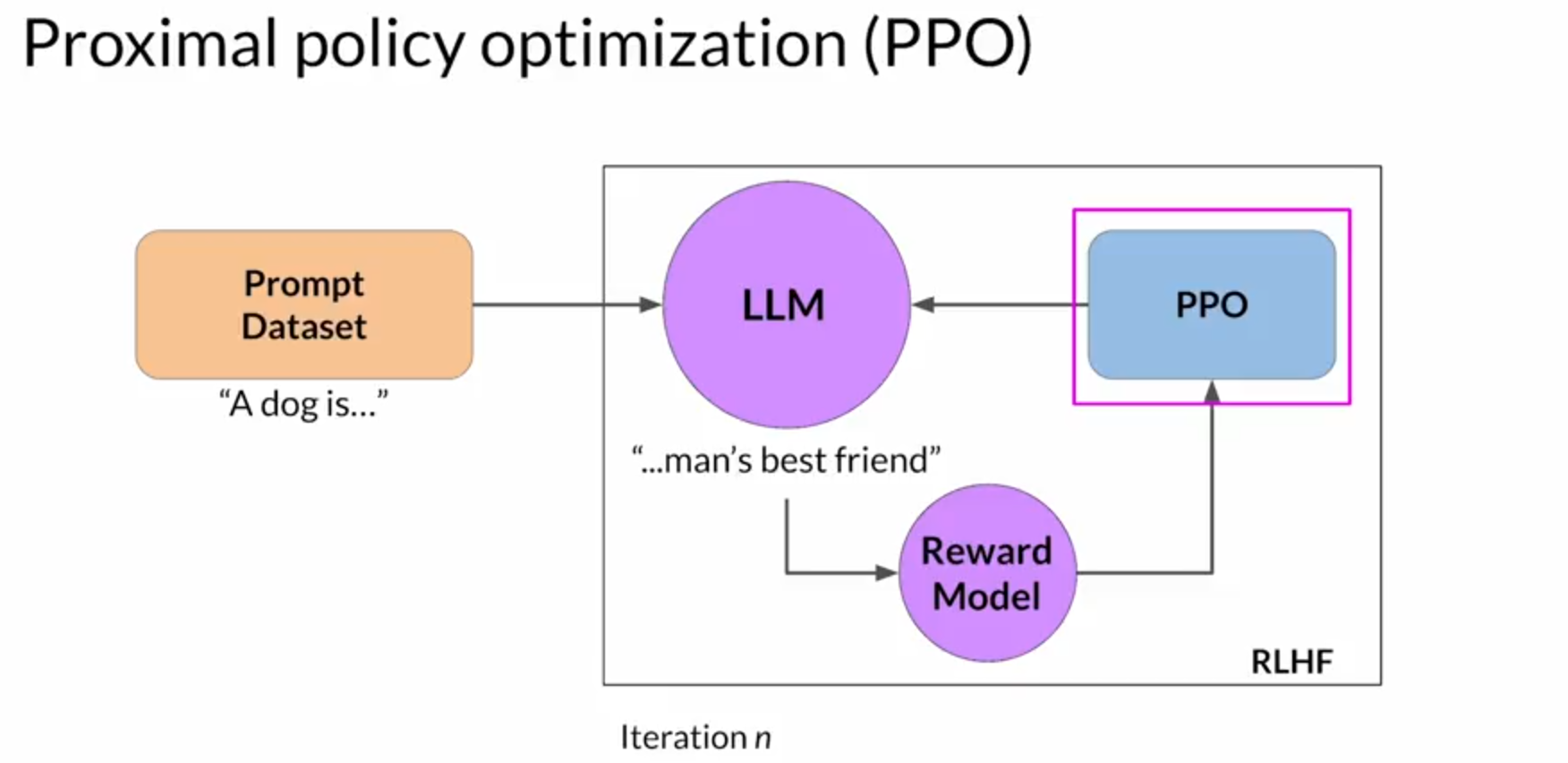
Courtsey: DeepLearning
Here’s how PPO parallels a student’s graceful learning journey:-
Step 1 (Feedback-Driven Improvement): The model generates a response.
A reward model, trained on human rankings, scores it based on helpfulness, safety, and relevance.(For the student: like a mentor grading each project.)
Step 2 (Measuring Advantage):The model calculates how much better or worse the response was compared to its baseline , the Advantage.Good actions (positive advantage) are encouraged; poor ones are suppressed. (For the student: high project scores reinforce good learning habits.)
Step 3 (Safe Updates with Clipping):PPO clips large updates to prevent sudden, extreme behavior shifts, keeping changes within safe margins. (For the student: don’t radically change methods after one feedback but adapt carefully.)
Step 4 (Anchoring with KL Divergence Penalty): PPO adds a KL (Kullback-Leibler) divergence penalty if the model strays too far from its original pre-trained behavior. (For the student: while learning new skills, never forget your foundational math, statistics, and programming.)
Step 5 (Optimizing the Final PPO Objective): The PPO loss function elegantly balances reward maximization with stability.
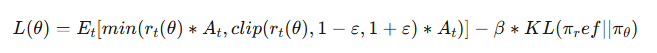
- The first term encourages learning from good feedback.
- The second term penalizes excessive divergence from core knowledge.
In practice, we maximize rewards by minimizing the negative of this loss.
Innovation with Deep Fundamentals: Architectural brilliance will open new doors. But deep, safe optimization e.g. mastering strategies like PPO , will ensure that models evolve gracefully, remain trustworthy, and align with human needs.
As India embarks on the ambitious journey of building its own foundational AI models, we stand at a critical crossroads: whether we simply build bigger models or build them smarter, safer, and more gracefully. True leadership in AI will not come just from scaling parameters, but from mastering the art of thoughtful fine-tuning, balancing innovation with deep optimization fundamentals like PPO, balancing growth with grounding, and
balancing speed with responsibility. Just as a great data scientist evolves through careful specialization without losing core strength,India’s AI platforms must evolve thoughtfully, preserving the vast learning of pre-training while adapting with agility to the real-world needs of agriculture, healthcare, water management, education, governance, and more.